
Helping enterprises leverage AI for a data-driven edge
We’ll transform your data into a competitive advantage. Since 2016, BigHub has been helping enterprises consult and develop AI strategies, handle data engineering, and launch custom AI solutions.
















.avif)



Tailor made AI applications
Looking for a custom AI solution? We provide end-to-end services with expertise in applied AI, including Gen AI features like knowledge bases and assistants. Our experts also specialize in machine learning for demand forecasting, cross-selling/upselling etc.
AI strategy and consulting
BigHub is your consulting and delivery partner for enterprise AI. We work with your teams to identify the highest-value use cases, assess feasibility and ROI, and define a tailored AI roadmap that turns opportunities into measurable business results. From there, we can support implementation end-to-end—covering data readiness, governance, and production rollout. We also manage EU AI Act compliance on your behalf, including risk assessment, documentation, and the controls needed to deploy AI responsibly.
Data engineering services
What if you could have cost-effective, scalable solutions that grow with your business? We specialize in Enterprise data platforms, cloud infrastructure optimization, and strengthening Data engineering capabilities.
AI's impact on your business is what matters to us
The uniqueness of collaborating with BigHub.
Business first
Data & AI as Software

Long-term partner

Specializing in AI solutions across industries
Explore the specific challenges we resolve for clients across diverse sectors.
Fraud detection in logistics

Solution for unauthorized electricity theft

Enhancing demand prediction in retail

AI securely transforming banking and insurance operations

Improving the precision of patient diagnostics in healthcare

AI driving efficiency and resilience in manufacturing
Anticipate what comes next
Prices that adapt to real demand
Faster, smarter customer care

Faster liquidity, smoother processes

Pay only for what you use
Generative AI you can trust
What clients value about BigHub
Read feedback from our trusted business partners.

"The AI Assistant was built from the beginning on strong collaboration and trust. Even without prior experience, I was able to quickly find my footing thanks to the support and guidance of the BigHub team. The result is a solution that has been very positively received by colleagues – we currently have over 800 active users."

“What used to take 10 minutes of searching now takes 10 seconds. When our team started two years ago, we knew it wouldn’t be easy. But now, seeing PROKOOP in action, hearing the positive feedback, and holding the VIG XELERATE award in my hands — I know it was all worth it.”

"Customer feedback on the automated claims processing has been very positive. The significant acceleration of case resolution, simplified communication, and the system’s ability to decide on payouts within minutes all improve the overall customer experience."


"For implementing AI-driven processes in our e-commerce platform, we were looking for a partner who could combine innovation with practical application. In BigHub, we found a team supported by leading players in the AI field, which perfectly understands the latest technologies and can transform them into a functional solution that genuinely elevates our online sales and customer experience to the next level."


“With BigHub, we don’t waste time on generic sales presentations – we go straight to the point: use cases. Thanks to the right level of detail, we can run practical workshops with business teams, where we jointly identify opportunities with the highest return on investment. Each use case is developed systematically, allowing us to find synergies between them and take the use of AI at Sazka to the next level.”


"What I value most about working with BigHub is their combination of technological expertise and practical approach – they have real drive and a strong problem-solving mindset, always looking for solutions where others see obstacles. They were quick to adapt to changes and consistently found ways to move the project forward. I’m glad we’ve found in BigHub a partner who is both reliable and inspiring.”

The results were compelling enough to present to key shareholders, who approved production deployment of the BigHub solution. We also engaged BigHub in shaping our data strategy to improve access to critical data and business insight. BigHub was chosen as our partner for implementing the Big Data platform and gas network maintenance application.


"T-Mobile aimed to boost its AI capabilities to strenghten its competitive edge. We appreciate expertise of BigHub who led us through entire decision making process and implementation in terms of selection, acquisition, configuration and utilization of the GPU-powered analytics platform. Moreover, we highly value fusion of both deep learning and platform engineering skills when delivering real business solutions."


“The analytical tool from BigHub helped us to detect suspicious electric offtakes. Moreover, merging isolated data sources into one place allowed us to further analyze customer behavior and work on behavioral segmentation.”


What I value most about working with BigHub is their ability to connect deep AI expertise with practical business needs. Together, we successfully developed both a fresh bakery sales forecasting model and an AI shopping assistant focused on improving the customer experience.
BigHub acted not only as a technology provider, but as a true partner. Their team was able to respond quickly to changes, iterate on the solution, and stay focused on delivering measurable value. In the fast-evolving field of AI, I see their agility, product mindset, and results orientation as a significant competitive advantage.


„We would like to thank the BigHub team for their excellent collaboration on the implementation of AI assistant for our PLANEO branch network. After a previous experience with another provider, where the project stalled, we finally found a partner who is not only professional but also reliable and flexible.“


"We are collaborating with BigHub on an intelligent search project, and from the very beginning, we have been impressed by their enthusiasm, expertise, and excellent client-oriented approach. What we value most is their proactivity and agile mindset."


"Working with BigHub was highly professional. Clear communication and a well-defined scope from the start ensured an efficient process throughout. The included ML/AI knowledge transfer was valuable, and BigHub delivered exactly what was promised—on time and on budget."
.avif)

"We consider BigHub to be one of the top providers of AI and data solutions in the Czech Republic, which they consistently demonstrate through the projects we carry out together. They not only help us deliver these projects but also actively co-create them with us and proactively seek out opportunities to bring business value."

Discover how BigHub transforms businesses with AI in a wide range of fields
Actions speak louder than words. Explore tangible examples of our solutions.

AI agent system cuts document processing from 15 to 2 mins at Direct Pojistovna

Datart launched an AI assistant that boosts conversions and customer satisfaction

AI assistant PROKOOP, Kooperativa’s sales team cuts down on admin and focuses more on clients

How AI search helped AAA Auto boost engagement by 5% and simplify mobile navigation

AI solution that saves Fortuna 94% in costs and thousands of hours of work

From 3 days to 30 minutes: How NN pojistovna accelerated claim processing

How the AI assistant DIEGO accelerated operations at 100+ PLANEO stores

AI-powered VR solution makes ČPP presentation skill development 3x faster

How ČEZ uses AI to optimize operations: Powering energy innovation
Partners and certifications
Leveraging these partners, technologies, and certifications, we empower businesses to transform data into a competitive advantage.



Proud of our public success
What the media says about BigHub and who has recognized us.


"Czech BigHub isn’t afraid of big data or big challenges."
BigHub, established in 2016, specializes in cutting-edge data technologies, helps to innovate companies across all industries.

"ČEZ joins forces with BigHub to harness the power of AI."
BigHub was born when corporations failed to harness AI — now it’s one of the region’s fastest-growing companies.



Get your first consultation free
Want to discuss the details with us? Fill out the short form below. We’ll get in touch shortly to schedule your free, no-obligation consultation.
News from the world of BigHub and AI
We’ve packed valuable insights into articles — don’t miss out.

Why AI coding tools and new libraries should not run directly on your Mac
When people discuss security around vibe coding tools today, it often sounds as if this were a completely new problem. In reality, it is not new at all. Over the past few years, we have simply become used to running third-party code, third-party dependencies, and increasingly also third-party shell commands directly on our local machines — the same machines where we keep SSH keys, .env files, logged-in browsers, cloud access, and often even production credentials.
AI tooling did not create this problem. It only amplified it and made it much more visible.
On macOS, I think this is particularly obvious. Many people do not want to develop in Docker because the developer experience quickly deteriorates and containers on Mac still come with overhead. So the real default remains the same: everything runs on the host machine, and we hope nothing happens.
This works exactly until it does not.
LiteLLM only reminded us of an old problem
On March 24, 2026, compromised versions of litellm 1.82.7 and 1.82.8 appeared on PyPI. This was not an exotic exploit. A simple pip install was enough to introduce a malicious .pth file into the environment, which then executed when Python started.
It then reached for the kind of things that are typically easy to find on a developer machine:
- SSH keys
.envfiles- cloud credentials
- other secrets and configuration files
It then sent them to a remote server.
The important thing about this incident is how banal the attack path was. It did not need to break Python, bypass the kernel, or convince someone to run anything unusual. It only needed a developer to do what developers do every day: install a dependency.
Paradoxically, the whole thing may have been discovered faster because the malware was not written very well and triggered a fork bomb on some machines. If it had kept a lower profile and only exfiltrated data silently, it is quite possible that it would have remained unnoticed for longer.
In my view, a large share of regular developers would have been vulnerable to this — not only people experimenting with vibe coding. The reason is simple: very few people have their local Python environment truly isolated.
The JavaScript world was not doing much better either
This is not only a Python story.
On March 30 and 31, 2026, axios — one of the most widely used libraries in the JavaScript world — was also compromised. The attacker took over a maintainer account on npm and published malicious versions axios@1.14.1 and axios@0.30.4.
What is interesting is that the malicious payload was not directly inside axios itself. Those versions only added a new transitive dependency, plain-crypto-js, which executed through a postinstall hook. In other words, even here, an ordinary install was enough to turn the dependency chain into an execution chain.
That is exactly why I find it dangerous to pretend that supply-chain risk only applies to dubious packages at the edge of the ecosystem. It does not. Last week, this became visible in one of the most common HTTP clients for Node.js.
exclude-newer is a reasonable default
One of the few low-cost guardrails that makes sense for almost everyone is not installing completely fresh package releases immediately.
In uv, you can use exclude-newer, which limits dependency resolution to packages published before a selected date:
[tool.uv]
exclude-newer = "2026-03-24"
This is not a magic defense. It only buys you time. If you keep, for example, a 14-day delay, there is a reasonable chance that a compromised release will be discovered during that time and either removed or at least flagged by the community.
The same logic applies to AI coding tools
Just as you do not want to blindly run fresh dependencies on the host machine, you also do not want to run a code generator on the host machine with full access to everything around it.
This is not an argument against Codex, Claude Code, or any other tool. It is an argument against the amount of trust we give these tools by default.
Lightweight sandboxes are a good start. Codex CLI on macOS has historically used sandbox-exec, which can significantly limit where a process is allowed to reach. In Claude Code, sandboxing can be enabled via /sandbox. In both cases, this is significantly better than a mode where the agent can see the whole disk and run shell commands without restrictions.
This has two practical advantages:
- the agent typically sees only the repository or explicitly allowed paths
- you do not need to approve every small action just to maintain at least some control surface
For regular reading, file editing, and part of shell work, this is actually a useful middle ground.
Where this model hits its limits
The problem is that a lightweight sandbox is not the same as real isolation.
As soon as the tool needs to do something slightly more practical, the edges start to show:
- package installation through
uv,pip,npm, or similar tools often touches global caches - browser tooling may not work well inside the sandbox, or may not work at all
- some MCP servers need access outside the repository boundary
- sooner or later, you run into a command that simply has to be executed outside the sandbox
And at that moment, the vibe coder is asked whether the system can leave the sandbox — and most people simply click “Yes”.
That is why I think it is important not to confuse “it has some sandbox mode” with “it is safely isolated”.
What I think makes more sense
If we want to use agents or code generators seriously, we need a real sandbox. Ideally, a separate VM or microVM for each project. On Mac, this could be something like Lima or a similar VM-based solution. Docker sandboxes follow a similar direction in principle, although on macOS they often run into performance and developer-experience issues.
But the point is not the specific product. The point is the trust boundary.
Into such an environment, you move only what the specific project actually needs:
- repository checkout
- project-scoped credentials
- local cache dedicated only to that project
- optionally a browser session or MCP servers, but again only where it makes sense
This reduces the blast radius twice.
First: if the agent runs a destructive command such as rm -rf /, it destroys at most its own sandbox.
Second: if you install a compromised dependency such as an infected litellm, it cannot exfiltrate all credentials from the entire laptop. At worst, it gets access to what you placed into that specific environment. Ideally, that means only development secrets for one project.
That is still not a pleasant incident. But it is an order of magnitude better incident.
A classifier is useful, but it is not a sandbox
Claude Code has now also added an auto mode, where another classifier runs over more sensitive actions. It evaluates the transcript and individual tool calls, especially Bash commands and other actions outside the repository, and tries to block things such as data exfiltration, credential hunting, or destructive actions outside the scope of the task.
That is a reasonable step forward. Approval fatigue is real, and manually confirming everything is not a very sustainable model.
But even here, I think it is important to keep the right expectation: a classifier is a guardrail, not isolation.
It also does not solve the supply-chain problem. If you install a malicious package inside a trusted environment, a classifier watching Bash commands will not help you against what that package does during import or interpreter startup.
What I would take from this as a practical default
My current take is simple:
- do not run completely fresh dependencies without a delay
- do not run AI coding tools directly on the host machine with full access
- when using a lightweight sandbox, do not treat it as the final solution
- for more important work, use a per-project isolated environment with a limited blast radius
All of this was true long before someone came up with the term vibe coding.
There is just much less room to avoid it now. When you give an agent shell access, filesystem access, browser access, and credentials, you are effectively giving it very strong permissions. And as the LiteLLM incident showed, a regular package manager receives similarly strong permissions the moment you allow it to install third-party code directly on your laptop without isolation.
This is not a niche security debate. It is a fairly basic engineering default that we should have had in place a long time ago.
Apple is currently working on a new container engine, which I hope will have a lot of this built in. Until then, I try to pay close attention whenever commands are executed outside the sandbox.
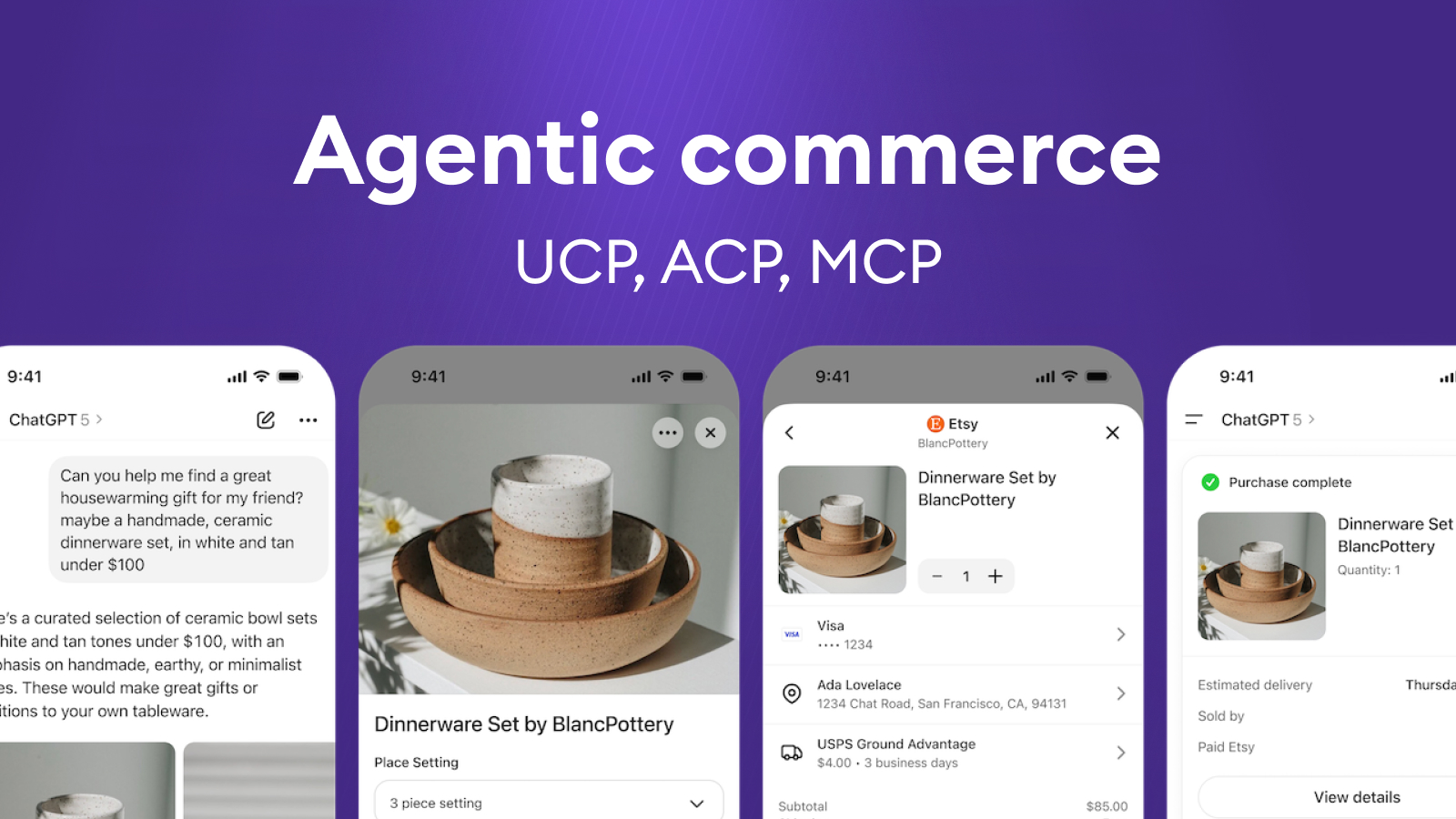
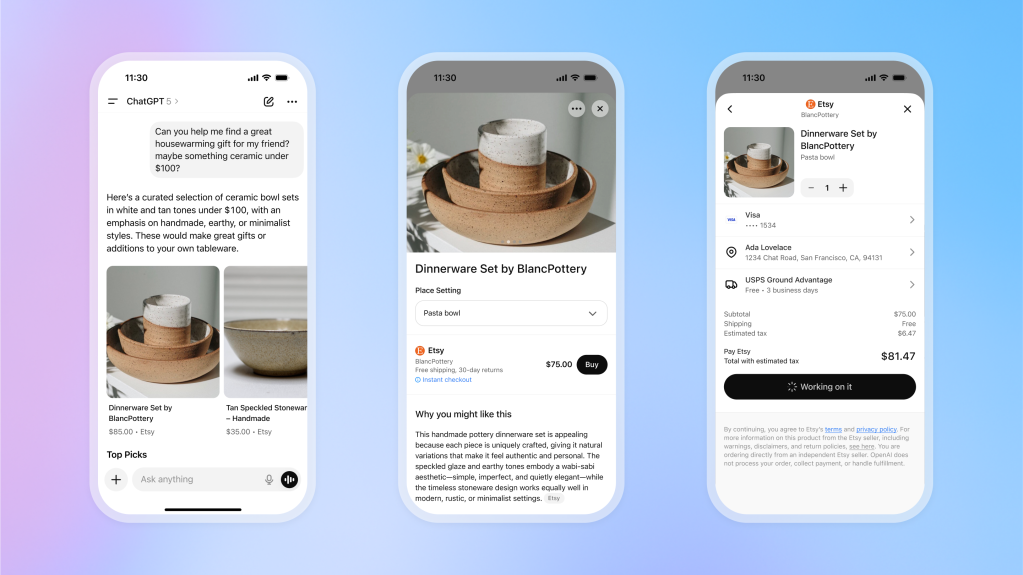
UCP, ACP, MCP in Agentic Commerce: AI is moving from “recommending” to “doing”
Where are we now
Over the last few months, several important things have happened in AI and e-commerce:
- Google introduced UCP (Universal Commerce Protocol) – an open standard for agentic commerce that unifies how an AI agent talks to a merchant: catalogue, cart, shipping, payment, order.
- OpenAI and Stripe launched ACP (Agentic Commerce Protocol) – a protocol for agentic checkout in the ChatGPT ecosystem.
- At the same time, MCP (Model Context Protocol) has emerged as a general way for agents to call tools and services, and OpenAI Apps SDK as a product/distribution layer for agent apps.
In other words, the internet is starting to define standardised “rails” for how AI agents will shop. And the market is shifting from “AI recommends” to “AI actually executes the transaction”.
In this article, we look at:
- what agentic commerce means in practice,
- how UCP, MCP, Apps SDK and ACP fit together,
- what these standards solve – and what they very intentionally don’t solve,
- and where custom agentic commerce makes sense – the exact type of work we do at BigHub.
What Is Agentic commerce
Agentic commerce is a shopping flow where an AI agent handles part or all of the process on behalf of a person or a business – from discovery and comparison to payment.
A typical scenario:
“Find me marathon running shoes under $150 that can be delivered within two weeks.”
The agent then:
- understands the request,
- queries multiple merchants,
- compares parameters, reviews, prices and delivery options,
- builds a shortlist,
- and, once the user approves, completes the purchase – ideally without the user ever touching a traditional web checkout.
This doesn’t only apply to B2C. Similar patterns show up in:
- internal procurement,
- B2B ordering,
- recurring replenishment,
- service and returns flows.
The direction is clear, AI is moving from “help me choose” to “get it done for me”.
MCP, Apps SDK, UCP and ACP
It’s useful to see today’s stack as layers.
MCP (Model Context Protocol) is:
- a general standard for how an agent calls tools, APIs and services,
- domain-agnostic (“I can talk to CRM, pricing, catalogue, ERP, …”),
- effectively the way the agent “sees” the world – through capabilities it can invoke.
In short: MCP = how the agent reaches into your systems.
OpenAI Apps SDK:
- provides UI, runtime and distribution for agents (ChatGPT Apps, user-facing interface),
- lets you quickly wrap an agent into a usable product:
- chat, forms, actions,
- distribution inside the ChatGPT ecosystem,
- basic management and execution.
In short: Apps SDK = how you turn an agent into a product people actually use.
UCP – Domain standard for commerce workflows
UCP (Universal Commerce Protocol) from Google and partners:
- is a domain-specific standard for commerce,
- unifies how an agent talks to a merchant about:
- catalogue, variants, prices,
- cart, shipping, payment, order,
- discounts, loyalty, refunds, tracking and support,
- is designed to work across Google Search, Gemini and other AI surfaces.
In short: UCP = the concrete language and workflow of buying.
ACP – Agentic checkout in the ChatGPT ecosystem
ACP (Agentic Commerce Protocol) from OpenAI/Stripe:
- targets a similar domain from the ChatGPT side,
- focuses strongly on checkout, payments and orders,
- powers features like Instant Checkout in ChatGPT.
From a merchant’s point of view, UCP and ACP are competing commerce standards (no one wants three different protocols in their stack).
From an architecture point of view, they can coexist as different dialects an agent uses depending on the channel (ChatGPT vs. Google / Gemini).
What these standards do – and what they don’t
The common pattern is important. UCP and ACP do not make agents “smart”. They just give them a consistent language.
These standards typically cover:
- how the agent formally communicates with the merchant and checkout,
- how offers and orders are structured,
- how payment and authorisation are handled securely,
- how a purchase can flow across different AI channels.
They do not (and cannot) solve:
- the quality and structure of your product catalogue, attributes and availability,
- integration into ERP, WMS/OMS, CRM, loyalty, pricing engine, campaign tooling,
- your business logic – margin vs. SLA vs. customer experience vs. revenue,
- governance, risk, approvals – who is allowed to order what, when a human must step in, how decisions are audited.
Practically, this means:
- you can be formally “UCP/ACP-ready”,
- and still deliver a poor agent experience if:
- data is inconsistent,
- delivery promises can’t be kept,
- pricing and promo logic breaks in a multi-channel world,
- the agent has no access to real-time states and internal rules.
The standard is a necessary technical minimum, not a finished solution.
How we approach Agentic Commerce at BigHub
At BigHub, we see UCP, MCP, ACP and Apps SDK as infrastructure building blocks. On real projects, we focus on what creates actual competitive advantage on top of them.
We build ML-powered commerce agents that can:
- optimise dynamic offers and pricing (bundles, alternatives, smart trade-offs based on margin, SLA and priorities),
- deliver personalised search and shortlists (customer context, preferences, budget, interaction history),
- handle argumentation and objections (why this option, what are the alternatives, explain the trade-offs),
- and only then smoothly push the checkout over the finish line.
On top of that, we add an integration layer via MCP (capabilities + connections to core systems). For UI and distribution, we often use OpenAI Apps SDK when we need to get an agent in front of real users quickly. Where it makes sense, we plug into standards like UCP/ACP instead of writing bespoke integrations for every single channel.
Where custom Agentic Commerce makes the difference
Standards (UCP/ACP/MCP) are extremely valuable where:
- you don’t want to invent your own protocol for connecting to AI channels,
- you need interoperability (ChatGPT, Google/Gemini, others),
- you want to reduce integration overhead for merchants.
A custom approach adds the most value in these areas:
1) Connecting the agent to core systems
- ERP, WMS/OMS, CRM, loyalty, pricing, returns, contact centre…
- the agent must live in your real operational architecture, not a demo sandbox.
Typically you need a dedicated integration and orchestration layer that:
- speaks UCP/ACP/MCP “upwards”,
- speaks your specific systems and APIs “downwards”.
2) Domain logic and business Rules
This is where competitive advantage is created:
- when the agent can execute autonomously vs. when it should only recommend,
- how it balances margin, SLA, availability, customer experience and revenue,
- how it works with promotions, loyalty, cross-sell / up-sell scenarios.
This is not a protocol question. It’s about concrete rules on top of your data and KPIs.
3) Multi-channel and the mix of B2C / B2B / Internal agents
Real-world commerce looks like this:
- B2C webshop,
- B2B ordering portal,
- internal purchasing agent,
- in-store sales assistant,
- customer service agent.
A custom framework lets you:
- share logic across roles and channels,
- respect permissions and limits,
- support flows like “AI starts in chat, finishes in the store”.
4) European context: Regulation, security, Data residency
For European companies, several constraints matter:
- regulation (EU AI Act, GDPR, sector-specific rules),
- internal security posture, audits, risk controls,
- where data and models actually run (US vs. EU),
- how explainable and auditable agent decisions are.
Standards are global, but architecture and governance have to be local and tailored.
What retailers and enterprises should take away from UCP (and other similar protocols)
If you’re thinking about agentic commerce, it’s worth asking a few practical questions:
- Are we “agent-ready” not only at the protocol level, but also in terms of data and processes?
- In which use cases do we actually want the agent to execute the transaction – and where should it stay at the recommendation level?
- How will agentic commerce fit into our existing systems, pricing, campaigns and SLAs?
- Who owns agent initiatives internally (KPI, P&L) and how will we measure success?
- Which parts make sense to solve via standards (UCP/ACP/MCP) and where do we already need a custom agent framework?
How to build intelligent search: From full-text to optimized hybrid search
The problem: Limits of traditional search
Classic full-text search based on algorithms like BM25 has several fundamental constraints:
1. Typos and variants
- Users frequently submit queries with typos or alternate spellings.
- Traditional search expects exact or near-exact text matches.
2. Title-only searching
- Full-text search often targets specific fields (e.g., product or entity name).
- If relevant information lives in a description or related entities, the system may miss it.
3. Missing semantic understanding
- The system doesn’t understand synonyms or related concepts.
- A query for “car” won’t find “automobile” or “vehicle,” even though they are the same concept.
- Cross-lingual search is nearly impossible—a Czech query won’t retrieve English results.
4. Contextual search
- Users often search by context, not exact names.
- For example, “products by manufacturer X” should return all relevant products, even if the manufacturer name isn’t explicitly in the query.
The solution: Hybrid search with embeddings
The remedy is to combine two approaches: traditional full-text search (BM25) and vector embeddings for semantic search.
Vector embeddings for semantic understanding
Vector embeddings map text into a multi-dimensional space where semantically similar meanings sit close together. This enables:
- Meaning-based retrieval: A query like “notebook” can match “laptop,” “portable computer,” or related concepts.
- Cross-lingual search: A Czech query can find English results if they share meaning.
- Contextual search: The system captures relationships between entities and concepts.
- Whole-content search: Embeddings can represent the entire document, not just the title.
Why embeddings alone are not enough
Embeddings are powerful, but not sufficient on their own:
- Typos: Small character changes can produce very different embeddings.
- Exact matches: Sometimes we need precise string matching, where full-text excels.
- Performance: Vector search can be slower than optimized full-text indexes.
A hybrid approach: BM25 + HNSW
The ideal solution blends both:
- BM25 (Best Matching 25): A classic full-text algorithm that excels at exact matches and handling typos.
- HNSW (Hierarchical Navigable Small World): An efficient nearest-neighbor algorithm for fast vector search.
Combining them yields the best of both worlds: the precision of full-text for exact matches and the semantic understanding of embeddings for contextual queries.
The challenge: Getting the ranking right
Finding relevant candidates is only step one. Equally important is ranking them well. Users typically click the first few results; poor ordering undermines usefulness.
Why simple “Sort by” is not enough
Sorting by a single criterion (e.g., date) fails because multiple factors matter simultaneously:
- Relevance: How well the result matches the query (from both full-text and vector signals).
- Business value: Items with higher margin may deserve a boost.
- Freshness: Newer items are often more relevant.
- Popularity: Frequently chosen items may be more interesting to users
Scoring functions: Combining multiple signals
Instead of a simple sort, you need a composite scoring system that blends:
- Full-text score: How well BM25 matches the query.
- Vector distance: Semantic similarity from embeddings.
- Scoring functions, such as:
- Magnitude functions for margin/popularity (higher value → higher score).
- Freshness functions for time (newer → higher score).
- Other business metrics as needed.
The final score is a weighted combination of these signals. The hard part is that the right weights are not obvious—you must find them experimentally.
Hyperparameter search: Finding optimal weights
Tuning weights for full-text, vector embeddings, and scoring functions is critical to result quality. We use hyperparameter search to do this systematically.
Building a test dataset
A good test set is the foundation of successful hyperparameter search. We assemble a corpus of queries where we know the ideal outcomes:
- Reference results: For each test query, a list of expected results in the right order.
- Annotations: Each result labeled relevant/non-relevant, optionally with priority.
- Representative coverage: Include diverse query types (exact matches, synonyms, typos, contextual queries).
Metrics for quality evaluation
To objectively judge quality, we compare actual results to references using standard metrics:
1. Recall (completeness)
- Do results include everything they should?
- Are all relevant items present?
2. Ranking quality (ordering)
- Are results in the correct order?
- Are the most relevant results at the top?
Common metrics include NDCG (Normalized Discounted Cumulative Gain), which captures both completeness and ordering. Other useful metrics are Precision@K (how many relevant items in the top K positions) and MRR (Mean Reciprocal Rank), which measures the position of the first relevant result.
Iterative optimization
Hyperparameter search proceeds iteratively:
- Set initial weights: Start with sensible defaults.
- Test combinations: Systematically vary:
- Field weights for full-text (e.g., product title vs. description).
- Weights for vector fields (embeddings from different document parts).
- Boosts for scoring functions (margin, recency, popularity).
- Aggregation functions (how to combine scoring functions).
- Evaluate: Run the test dataset for each combination and compute metrics.
- Select the best: Choose the parameter set with the strongest metrics.
- Refine: Narrow around the best region and repeat as needed.
This can be time-consuming, but it’s essential for optimal results. Automation lets you test hundreds or thousands of combinations to find the best.
Monitoring and continuous improvement
Even after tuning, ongoing monitoring and iteration are crucial.
Tracking user behavior
A key signal is whether users click the results they’re shown. If they skip the first result and click the third or fourth, your ranking likely needs work.
Track:
- CTR (Click-through rate): How often users click.
- Click position: Which rank gets the click (ideally the top results).
- No-click queries: Queries with zero clicks may indicate poor results.
Analyzing problem cases
When you find queries where users avoid the top results:
- Log these cases: Save the query, returned results, and the clicked position.
- Diagnose: Why did the system rank poorly? Missing relevant items? Wrong ordering?
- Augment the test set: Add these cases to your evaluation corpus.
- Adjust weights/rules: Update weights or introduce new heuristics as needed.
This iterative loop ensures the system keeps improving and adapts to real user behavior.
Implementing on Azure: AI search and OpenAI embeddings
All of the above can be implemented effectively with Microsoft Azure.
Azure AI Search
Azure AI Search (formerly Azure Cognitive Search) provides:
- Hybrid search: Native support for combining full-text (BM25) and vector search.
- HNSW indexes: An efficient HNSW implementation for vector retrieval.
- Scoring profiles: A flexible framework for custom scoring functions.
- Text weights: Per-field weighting for full-text.
- Vector weights: Per-field weighting for vector embeddings.
Scoring profiles can combine:
- Magnitude scoring for numeric values (margin, popularity).
- Freshness scoring for temporal values (created/updated dates).
- Text weights for full-text fields.
- Vector weights for embedding fields.
- Aggregation functions to blend multiple scoring signals.
OpenAI embeddings
For embeddings, we use OpenAI models such as text-embedding-3-large:
- High-quality embeddings: Strong multilingual performance, including Czech.
- Consistent API: Straightforward integration with Azure AI Search.
- Scalability: Handles high request volumes.
Multilingual capability makes these embeddings particularly suitable for Czech and other smaller languages.
Integration
Azure AI Search can directly use OpenAI embeddings as a vectorizer, simplifying integration. Define vector fields in the index that automatically use OpenAI to generate embeddings during document indexing.